昨天分享了資料預處理的一種,是用來將電腦可以分辨先後順序的資料進行處理,今天會再介紹兩種,那廢話不多說直接先來講第一種吧。
1.在辨識圖片這種資料時,電腦沒有辦法讀取2維圖片的值,這時我們就要將2維的圖片全部轉換成電腦能讀懂的1維向量,可以大量提高模型訓練的速度,例如一張長和寬皆為27像素的2維向量圖片,就要轉換成729(27*27)個數字的1維向量。而每張2維圖片的特徵都不一樣,所以他們轉換出來的729個數值都會不太一樣。
範例:
先利用Numpy和Matplotlib印出一張圖片
import numpy as np
import matplotlib.pyplot as plt
image = np.zeros((27, 27), dtype=np.uint8)
image[9:18, 9:18] = 255
plt.imshow(image, cmap='gray')
plt.show()
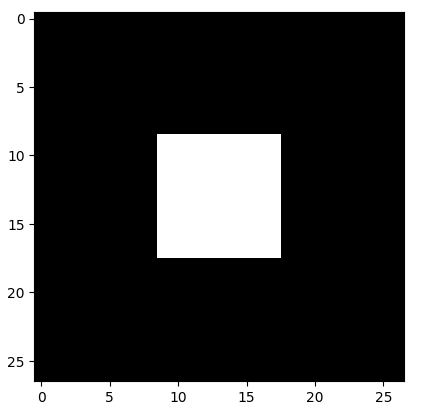
將這張2維像量圖片轉換成1維數字
image_flat = image.reshape(729)
print(image_flat)

在上面這個範例中我們成功將2維圖片轉換1維數字,但可以發現數字都是0和255,這是因為我舉的這個例子的每個區塊都只有全黑或全白,所以只會有兩種結果。但還有另一個問題,就是255這個數值是不是有點太大了,電腦會計算的時間會拉長很多,所以就到了第二種預處理的時間了,第二種處理方法叫做標準化(Normalize),它的作用是將過大的數字便成0到1之間的浮點數,其實只要將資料除上一個值就好了。
用上一個例子繼續做示範

這樣來看是不是就整齊多了呢


 iThome鐵人賽
iThome鐵人賽